
详细描述
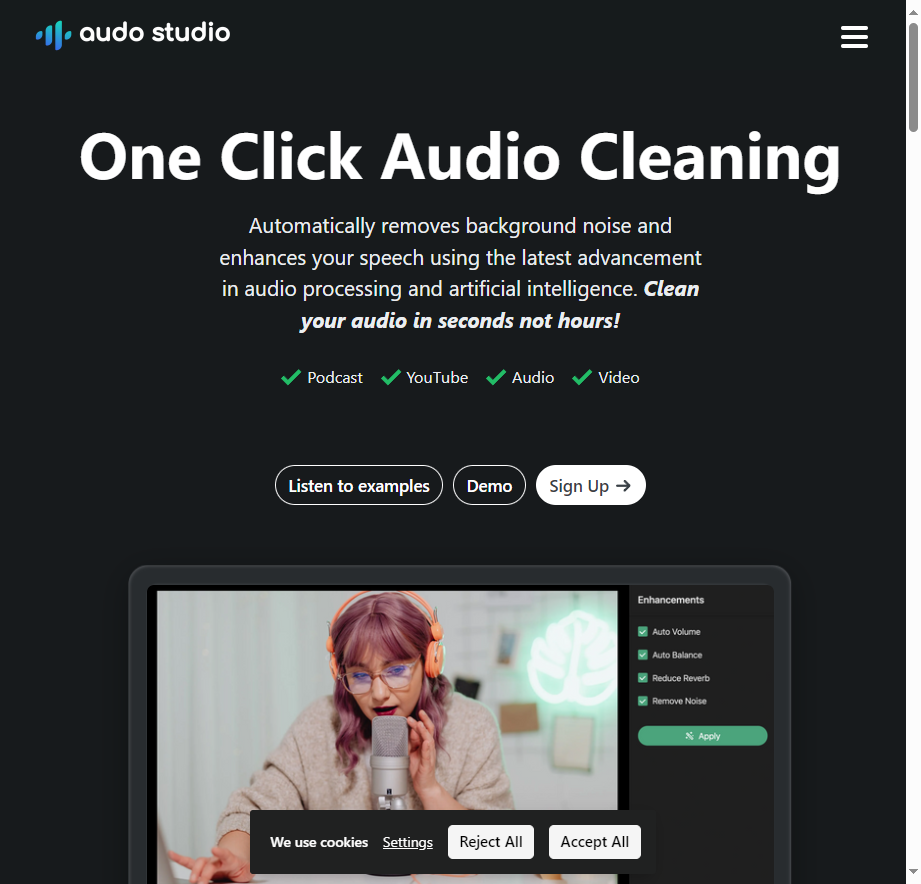
AI声音分离 Audo Studio 1. 简介 AI声音分离技术是一种利用人工智能技术从混合的音源中提取出单个声音的技术。
这项技术可以通过识别音频数据中的特征,去除不必要的噪音,只提取人声或其他特定乐器的声音。
这种技术可以用于各种应用场景,如音乐制作、音频编辑、声音设计等。
2. 技术实现 AI声音分离技术通常基于神经网络进行训练,使其能够学习和识别不同声音的特征。
在训练过程中,神经网络会接触到大量的音乐和其他声音,以便学习和区分这些声音。
一旦训练完成,这个系统就可以准确地从混合的音源中分离出所需的声音。
3. 应用案例 索尼公司就曾使用这项技术来修复电影的音轨,提取对话以及各种模拟声音。
此外,AI声音分离技术还可以用于清理通过麦克风记录的人类声音,提高语音识别能力。
在音乐制作领域,AI声音分离技术可以用于实时移除流媒体音乐中的人声,实现类似卡拉OK的体验。
4. 开发历程 AI声音分离技术的发展可以追溯到2013年,当时索尼引入了AI技术,在声音分离领域取得了重大突破。
自那时以来,随着人工智能技术的不断发展,AI声音分离技术也在不断进步,为用户提供更加先进和便捷的声音分离解决方案。
5. 优点 AI声音分离技术的优点在于它的高精度和高效性。
相比传统的音频处理方法,AI声音分离技术能够更准确地分离出所需的声音,同时处理速度更快。
此外,AI声音分离技术还具有很强的灵活性,可以适应不同的音源和声音环境,满足用户的各种声音分离需求。
6. 结论 AI声音分离技术是一项革命性的音频处理技术,它利用人工智能的力量,使得用户能够轻松地从混合的音源中提取出所需的声音。
随着这项技术的不断进步和完善,它在音乐制作、音频编辑、声音设计等领域的应用前景十分广阔。